-
Weakly Supervised Deep Depth Prediction Leveraging Ground Control Points for Guidance
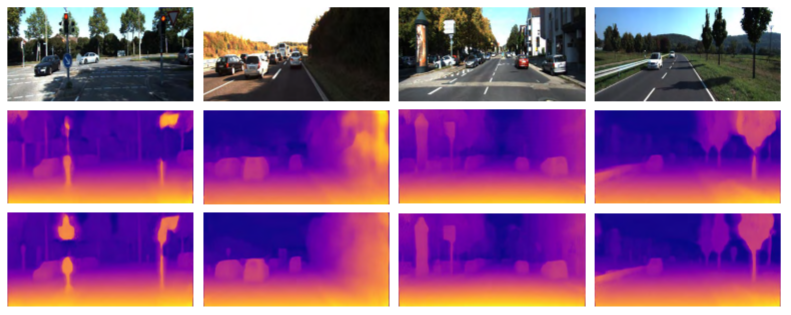
Despite the tremendous progress made in learning-based depth prediction, most methods rely heavily on large amounts of dense ground-truth depth data for training. To solve the tradeoff between the labeling cost and precision, we propose a novel weakly supervised approach, namely, the GuidedNet, by incorporating robust ground control points for guidance. By exploiting the guidance from ground control points, disparity edge gradients, and image appearance constraints, our improved network with deformable convolutional layers is empowered to learn in a more efficient way. The experiments on the KITTI, Cityscapes, and Make3D datasets demonstrate that the proposed method yields a performance superior to that of the existing weakly supervised approaches and achieves results comparable to those of the semisupervised and supervised frameworks.
-
SSF-DAN Separated Semantic Feature Based Domain Adaptation Network for Semantic Segmentation
Despite the great success achieved by supervised fully convolutional models in semantic segmentation, training the models requires a large amount of labor-intensive work to generate pixel-level annotations. Recent works exploit synthetic data to train the model for semantic segmentation, but the domain adaptation between real and synthetic images remains a challenging problem.
-
SemFlow Semantic-Driven Interpolation for Large Displacement Optical Flow
This paper presents a semantic-guided interpolation scheme (SemFlow) to handle motion boundaries and occlusions in large displacement optical flow. The basic idea is to segment images into superpixels and estimate their homographies for interpolation. In order to ensure each superpixel can be approximated as a plane, a semantic-guided refinement method is introduced. Moreover, we put forward a homography estimation model weighted by the distance between each superpixel and its K-nearest neighbors. Our newly-proposed distance metric combines the texture and semantic information to find proper neighbors. Our homography model performs better than the original affine model, since it accords with the real world projection relationship. The experiments on KITTI dataset demonstrate that SemFlow outperforms other state-of-the-art methods, especially in solving the problem of large scale motions and occlusions.
-
Robust Active Visual SLAM System Based on Bionic Eyes

Visual simultaneously localization and mapping (SLAM) systems obtain accurate estimation of the camera motion and the 3D map of the environment. Although the performance of SLAM systems is very impressive in many common scenarios, the tracking failure is still a very challenging issue, which always exists in the low textured environment and the rapid camera motion situation. In this paper, we proposed the first active bionic eyes SLAM system that leverages saccade movement of human eyes. In order to find more features points, we proposed an autonomous control strategy of the bionic eyes, which is mainly inspired by the peripheral and central visual of human eyes. Experimental results support that compared to fixed stereo cameras, our active bionic eyes SLAM system gains more robustness and avoids the tracking failure problem when facing the low textured environment.
-
Multilevel Cross-Aware RGBD Semantic Segmentation of Indoor Environments

Semantic segmentation is the main step towards scene understanding which is one of the most important tasks of computer vision. As the depth and color information are independent, the combination of depth and RGB images can improve the quality of semantic labeling. In this paper, we proposed a multilevel cross-aware network (MCA-Net) for RGBD semantic segmentation to jointly reason about 2D appearance and depth geometric information. Our MCA-Net utilizes basic residual structure to encode texture information and depth geometric information respectively