-
Multi-Dimensional Residual Dense Attention Network for Stereo Matching

Very deep convolutional neural networks (CNNs) have recently achieved great success in stereo matching. It is still highly desirable to learn a robust feature map to improve ill-posed regions, such as weakly textured regions, reflective surfaces, and repetitive patterns. Therefore, we propose an end-to-end multi-dimensional residual dense attention network (MRDA-Net) in this paper, focusing on more comprehensive pixel-wise feature extraction. Our proposed network consists of two parts: the 2D residual dense attention net for feature extraction and the 3D convolutional attention net for matching.
-
BVMSOD Bionic Vision Mechanism based Salient Object Detection

Salient object detection is proved to be important in vision tasks, and recent advances in this task is substantial, mostly benefiting from the explosive development of convolutional neural networks (CNNs). Extensive experiments demonstrate that our method is effective and robust in various scenes. This reveals that there are numerous essential mechanisms in the bionic and brain-inspired intelligence, which could be combined with deep learning method in various vision tasks.
-
A Hierarchical Attention Fused Descriptor for 3D Point Matching

Motivated by recent successes on learning 3D feature representations, we present a Siamese network to generate representative 3D descriptors for 3D point matching in point cloud registration. Our system, dubbed HAF-Net, consists of feature extraction module, hierarchical feature reweighting and recalibration module (HRR), as well as feature aggregation and compression module. The HRR module is proposed to adaptively integrate multi-level features through learning, acting as a hierarchical attention fusion mechanism. The experiments demonstrate that the proposed HAF-Net not only outperforms other state-of-the-art approaches in 3D feature representation but also has a good generalization ability in various tasks and datasets.
-
Stereo Visual-Inertial SLAM With Points and Lines
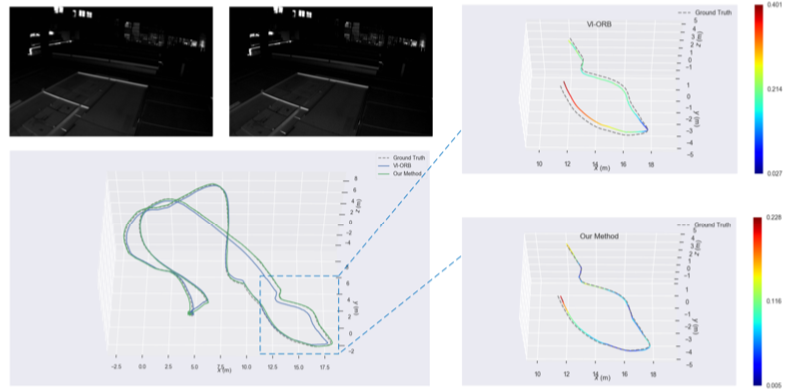
Visual–inertial SLAM systems achieve highly accurate estimation of camera motion and 3-D representation of the environment. Most of the existing methods rely on points by feature matching or direct image alignment using photo-consistency constraints. The cost function of bundle adjustment is formed by point, line reprojection errors, and IMU residual errors. We derive the Jacobian matrices of line reprojection errors with respect to the 3-D endpoints of line segments and camera motion. Loop closure detection is decided by both point and line features using the bag-of-words approach. Our method is evaluated on the public EuRoc dataset and compared with the state-of-the-art visual–inertial fusion methods. Experimental results show that our method achieves the highest accuracy on most of testing sequences, especially in some challengeable situations such as low textured and illumination changing environments.
-
Semantic Edge Based Disparity Estimation Using Adaptive Dynamic Programming for Binocular Sensors

Disparity calculation is crucial for binocular sensor ranging. The disparity estimation based on edges is an important branch in the research of sparse stereo matching and plays an important role in visual navigation. In this paper, we propose a robust sparse stereo matching method based on the semantic edges. Some simple matching costs are used first, and then a novel adaptive dynamic programming algorithm is proposed to obtain optimal solutions. This algorithm makes use of the disparity or semantic consistency constraint between the stereo images to adaptively search parameters, which can improve the robustness of our method. The proposed method is compared quantitatively and qualitatively with the traditional dynamic programming method, some dense stereo matching methods, and the advanced edge-based method respectively. Experiments show that our method can provide superior performance on the above comparison.